What is MongoDB..?
- NoSQL : RDBMS 다르게 고정된 스키마 존재 X
- Document-oriented DB (JSON 기반의 Document 기반 데이터 관리) : for Scaling Out
- 행(Column) 개념 대신 보다 유연한 Documenet 개념 사용
- 내장 도큐먼트와 배열 허용 : 복잡 계층 관계를 하나의 레코드로 표현 가능
- 도큐먼트의 키와 값을 미리 정의하지 않음 - 확장 가능 구조
- MongoDB는 분산 확장을 염두에 두고 설계됨 (도큐먼트를 자동으로 재분배 & 클러스터 내 데이터 양과 부하 조절 가능) - CRUD 이외의 DMBS 기능 지원 : 보조인덱스 지원, 집계 파이프라인, 특수 collection 등
- 동시성과 처리량 극대화를 위한 WiredTiger 스토리지 엔진에 opportunistic locking을 사용
- 이에 따라 캐시처럼 제한된 용량의 RAM으로 쿼리에 알맞는 인덱스를 자동으로 생성할 수 있음
MongoDB Concept
- MongoDB 데이터의 기본 단위는 document (관계형 데이터베이스의 행과 유사)
- 표현 방식은 map, hash, dictionary 와 같은 자료 구조를 갖는다 - MongoDB의 단일 인스턴스는 자체적인 collection을 갖는 여러 개의 독립적인 데이터베이스를 호스팅한다
- collection (관계형 데이터베이스의 테이블과 유사) : 도큐먼트의 모음
- collection은 dynamic schema를 갖는다 (하나의 컬랙션 내 도큐먼트들이 모두 다른 구조를 가질 수 있음)
- 모든 도큐먼트는 컬렉션 내에서 고유한 특수키인 _id 를 가진다 - MongoDB의 collection은 이름으로 식별된다
- 어떤 UTF-8 문자열이든 쓸수 있다
- subcollection의 namespace에 .(마침표) 문자를 사용해 컬렉션을 체계화한다
MongoDB Replication
MongoDB 에서 복제를 수행하기 위해 여러 인스턴스가 모인 묶음이 필요하다. 이처럼 복제를 수행하기 위한 인스턴스의 묶음을 Replica Set 이라고 부른다. Replica Set에는 Primary, Secondary, Arbiter 구성원이 있다.
1. Primary : Client와 읽기 및 쓰기 작업, 각각의 Replica Set에 오직 하나만 존재
2. Secondary : Primary 와 정보 동기화
3. Arbiter : 정보를 저장하지는 않고 Replica Set의 복구를 돕는다
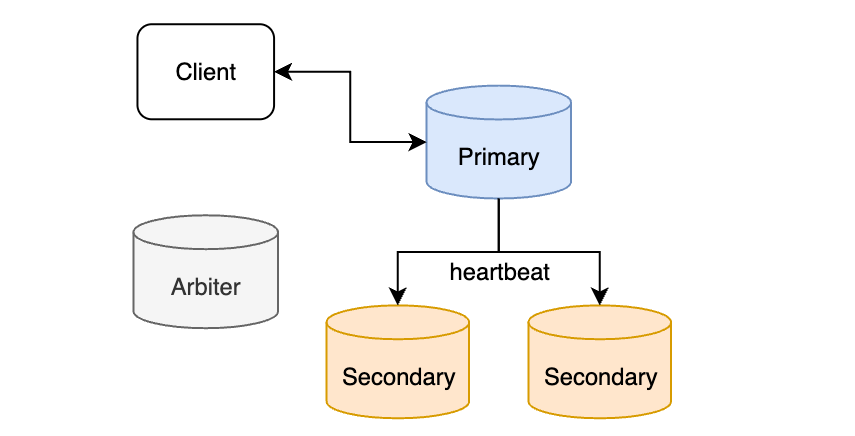
- Heartbeat : 인스턴스가 10초마다 핑을 보내 확인 (문제 발견 시 Priamry 구성원을 선출하는 선거에서 투표 진행)
| Primary | Secondary | Arbiter | |
| 주요 역할 | 클라이언트와 정보 교환 | 정보 복제 | 투표 진행 |
| 정보 저장 | O | O | X |
| 선거 역할 | 문제 발생 | 피선거권, 선거권 보유 | 선거권 보유 |
동기화 작동 방식
MongoDB는 동기화 방식으로 oplog(operation log: 인스턴스 내에서 변경된 정보 내역을 저장하는 특별한 Capped 컬렉션)를 활용한다. 예를 들어 어떤 도큐먼트를 쓰거나 지우면 oplog에 어떤 도큐먼트를 쓰거나 지웠는지에 대한 기록이 남는다.

[주의] oplog는 Capped 컬렉션이기 떄문에 시간이 지자면 오래된 정보를 지워진다. 만약 Secondary를 새로 추가했을 oplog의 정보만으로 동기화를 수행할 수 없을 때는, 초기 동기화를 수행하며 다닝 스레드로 처리되기 때문에(MongoDB 4.2 버전 기준) 시간이 오래 걸린다.
복제 관리
만약 Replica Set에서 대다수의 Secondary 인스턴스에 정보가 동기화가 안된다면 선거 이후 해당 변경점은 롤백된다.
따라서 중요 정보는 장애가 발생하더라도 모두 복구되도록 만들어야 한다. 이러한 설정은 ReadConcern & WriteConcern 옵션으로 설정 가능하다.
- ReadConcern 옵션 : Primary 에 기록된 정보를 가져올지, 아니면 대다수의 Replica Set에 저장된 정보를 가져올지 정할 수 있다
- WriteConcern 옵션 : ReplicaSet에 장애가 발생했을 때 정보가 사라질지, 유지될지 결정할 수 있다
| ReadConcern | local | 해당 인스턴스에 기록된 정보를 불러온다 |
| majority | Replica Set 대다수에 기록된 정보를 불러온다. | |
| linearizable | 제한된 시간에 탐색한 Replica Set의 Secondary에서 대다수의 구성원에 기록된 정보를 불러온다. | |
| WriteConcern | w | Replica Set의 어느 정도의 구성원에 쓰기 작업이 완료되어야 전체 쓰기 작업 완료 판단 |
| j | 쓰기 작업을 메모리에 변경 사항을 저장, 이후 일정 주기로 디스크에 변경 사항 기록(저널링) | |
| wtimeout | 쓰기 작업에 대한 제한 최대 시간 설정 (0, 1, 1보다 큰 자연수, majority) |
# 만약 Replica Set에 장애가 일어나더라도 정보의 손실을 막고 싶은 경우 write concern을 다음과 같이 설정하면 된다.
{ w: "majority", j: true }
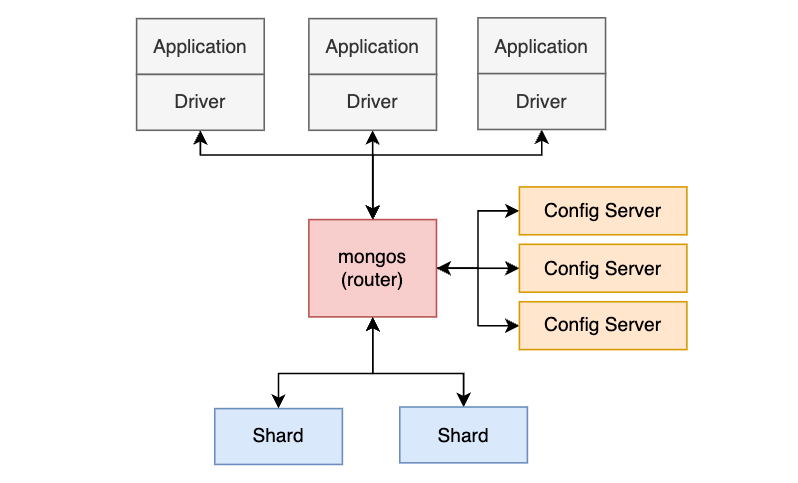
MongoDB Sharding
MongoDB는 데이터 일관성을 유지하기 위해 Config Server를 두어 관리한다.
Sharding은 여러 장비에 걸쳐 데이터를 분할하는 과정을 일컬으며, 때때로 Partitioning이라는 용어로도 불린다.

- Shard : 애플리케이션이 사용할 데이터를 나누어 저장
- 샤드는 라우터를 통해서만 애플리케이션과 데이터 정보 교환 가능 (각각의 샤드는 복제 세트를 가질 수 있다) - Config Server : 샤드 클러스터가 작동하기 위해 필요한 메타데이터를 저장
- 각각의 샤드에 어떤 정보가 들어있는지, 샤드 클러스터가 동작한 로그와 같은 정보 보관 - Router : 라우터는 직접 드라이버의 명령을 받아 어떤 작업을 수행할지 판단하고 결과를 드라이버에게 전달하는 역할 수행
- Config Server의 메타데이터를 캐싱하여 알맞은 샤드에 명령을 보내 원하는 정보를 가져온다
- mongos 프로세스(라우터 역할), mongod 프로세스 (드라이버 역할)
Percona Operator for MongoDB
PSMDB (Percona Server for MongoDB) 특징
- WiredTiger Storage Engine 사용 (MongoDB 기본 스토리지 엔진)
- 서버가 시작되면 checkpointing 과 저널링 프로세스를 시작
- 운영체제와 함께 작동(데이터 디스크로 플러시 및 페이징 중점)
- 기본 압축 알고리즘 : snappy
- 도큐먼트 수준의 동시성은 컬렉션에 있는 여러 클라이언트의 서로 다른 도큐먼트를 동시에 갱신할 수 있게 함
- 다중 버전 동시성 제어 MultiVersion Concurrency Control (MVCC) 을 사용해 읽기와 쓰기 작업을 격리함으로써, 작업 시작 시 데이터의 일관된 특정 시점 뷰를 클라이언트가 볼 수 있게 함
- checkpointing = 스냅샷 생성 (스냅샷의 모든 데이터를 디스크에 쓰고 관련 메타데이터를 갱신 작업 포함)
- 저널링은 mongod 프로세스 실패 시 데이터가 손실되는 시점이 없게 한다. 와이어드타이거는 수정 사항을 적용하기 전에 저장하는 로그 선행 기입(저널)을 사용한다.
https://docs.percona.com/percona-operator-for-mongodb/index.html
Percona Operator for MongoDB
Contact Us For free technical help, visit the Percona Community Forum. To report bugs or submit feature requests, open a JIRA ticket. For paid support and managed or consulting services , contact Percona Sales.
docs.percona.com
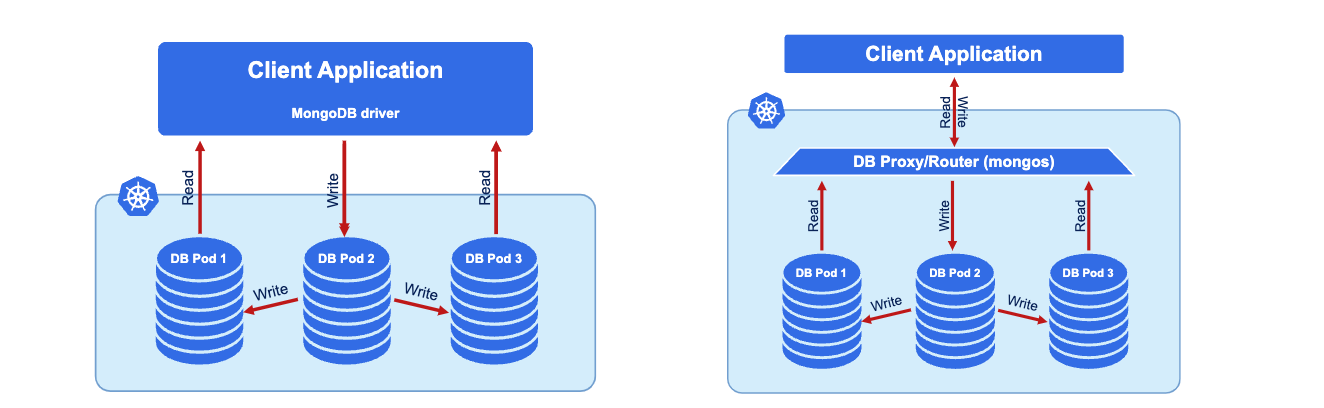
Percona Operator는 PSMDB를 생성, 변경, 삭제를 관리한다. 최소 3개 노드 사용을 요구하며
오퍼레이터는 Replica Set 또는 Sharded Cluster로 구성할 수 있다.
'DevOps > DOIK (Database Operator in Kubernetes)' 카테고리의 다른 글
| PostgreSQL Operator for Kubernetes (0) | 2023.10.31 |
|---|---|
| MySQL Operator for Kubernetes (0) | 2023.10.26 |
| MySQL Architecture & Replication (0) | 2023.10.24 |
| Kubernetes Basic (0) | 2023.10.21 |



